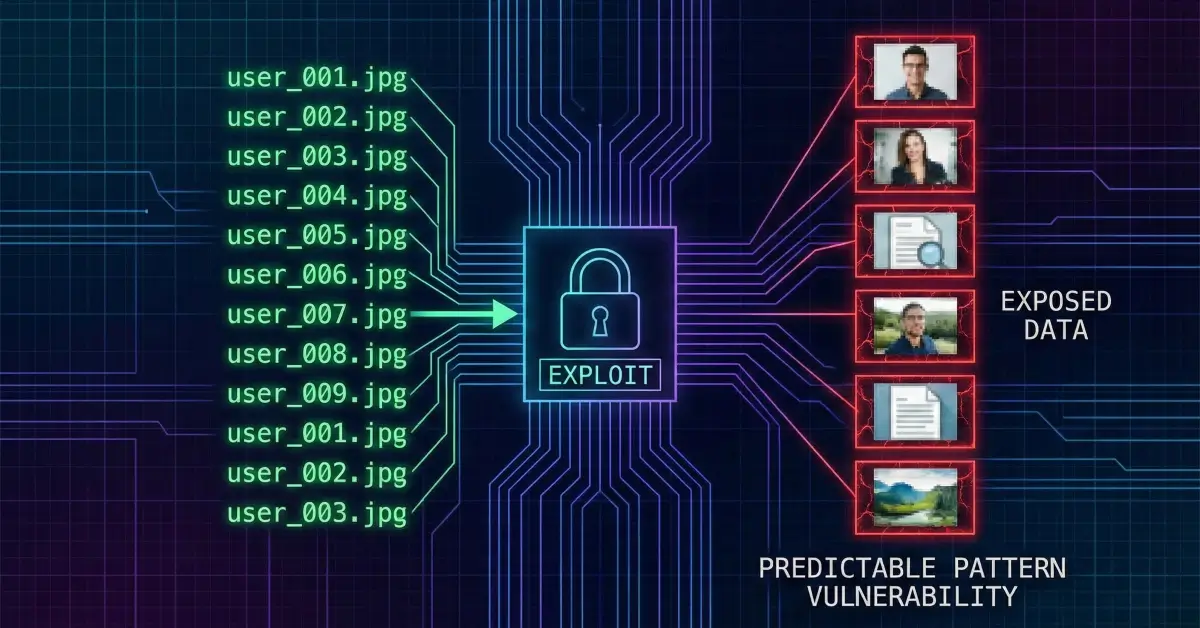
Predictable Filenames, Predictable Failure: When Image Downloads Become an IDOR Goldmine
A deep, defensive walkthrough of a real-world IDOR caused by predictable upload filenames, showing how reverse-engineering IDs and timestamps exposed private user images - and what this teaches about secure design.
Disclaimer
This article is published strictly for educational and defensive security purposes.
All domain names, identifiers, and sensitive details have been anonymized.
The vulnerability discussed was responsibly disclosed and resolved.
Do not attempt to test or exploit systems without explicit authorization.
Introduction
Not every high-impact vulnerability starts with a complex exploit chain or an obscure protocol edge case. Sometimes, it begins with something deceptively simple: a filename.
This write-up explores a real-world Insecure Direct Object Reference (IDOR) vulnerability hidden inside a background image removal feature. At first glance, the endpoint appeared harmless - a simple image download link. But under closer inspection, its design choices turned it into a quiet data-exposure machine.
The core issue wasn’t missing authentication.
It wasn’t even a broken permission check in the traditional sense.
It was predictability.
By reverse-engineering how uploaded images were named, an attacker could systematically enumerate and access other users’ private images, without ever interacting with those users or their accounts.
This blog reframes the original researcher’s discovery as a lesson in secure object design, predictable identifiers, and why “security by obscurity” fails - especially at scale.
High-Level Summary
- Vulnerability Class: Insecure Direct Object Reference (IDOR)
- Affected Feature: Image download endpoint
- Attack Prerequisites: Valid filename pattern knowledge
- User Interaction Required: None
- Impact: Unauthorized access to private user images
- Severity: Medium–High (Confidentiality impact, scoped by predictability)
The Feature That Looked Too Boring to Matter
The target application offered a background image removal feature. Users could upload an image, process it, and later download the cleaned version. For usability reasons, uploaded images were stored for 30 days.
During normal usage, when a user clicked “Download,” the browser made a request like:
Visiting the URL directly triggered an immediate file download. Nothing unusual there - thousands of applications implement similar functionality.
But one question naturally followed:
What happens if the filename belongs to someone else?
First Signal: Direct Object Access
Testing quickly revealed that the server performed no ownership verification on the requested file. If the filename existed, the server returned it - regardless of who requested it.
That confirmed a classic IDOR condition:
- Object identifier fully controlled by the client
- No authorization check tying the object to the requester
However, the program’s triage team raised a valid objection:
“How would an attacker realistically obtain another user’s filename?”
That’s where this bug evolved from simple to interesting.
Reverse-Engineering the Filename Structure
Looking closely at multiple downloaded images revealed a consistent naming pattern:
Breaking it down:
<id>
A six-digit numeric value that incremented sequentially with new uploads or accounts.<username>
The name chosen during account creation.<timestamp>
A Unix timestamp corresponding to the upload time.
None of these components were random. None were cryptographically protected. All were, to varying degrees, predictable.
This immediately changed the threat model.

Why Predictability Is Dangerous
Individually, each component seemed harmless:
- Sequential IDs are common.
- Usernames are often public.
- Timestamps are inevitable.
But when combined into a direct object reference, they created a pattern that could be reconstructed - and therefore abused.
This is a classic example of compound predictability:
Multiple weak signals, when chained together, become a strong attack vector.
Step-by-Step Attack Reasoning (Conceptual)

Step 1: Learning the Pattern
By uploading multiple images and observing their filenames, the structure became clear and repeatable.
No guessing required - just observation.
Step 2: Enumerating Sequential IDs
Since IDs increased monotonically, it was possible to:
- Start from a known ID
- Walk backward to older uploads
- Test whether files still existed within the 30-day retention window
Some requests returned 404. Others returned valid images.
That alone confirmed enumeration was viable.
Step 3: Timestamp Prediction
The timestamp added complexity - but not protection.
Upload times cluster around predictable windows:
- Recent days
- Working hours
- Peak usage periods
By generating timestamps within plausible ranges and combining them with enumerated IDs, hundreds of candidate filenames could be produced.
Each request was lightweight. Each response immediately confirmed success or failure.
Why This Wasn’t Trivial in Practice
This wasn’t a one-click exploit.
The researchers faced:
- Silent failures (404 vs 403 inconsistencies)
- False positives
- Tight coupling between ID and timestamp accuracy
But persistence paid off.
Through scripting, filtering, and iteration, the internal naming logic was reverse-engineered with sufficient precision to demonstrate real, repeatable exposure.
Impact Analysis
What Was Exposed
- Private user-uploaded images
- Potentially sensitive personal content
- Files assumed to be visible only to their owners
What Was Not Required
- No authentication bypass
- No session hijacking
- No brute-force login attempts
- No exploitation of server-side code execution
This was a pure logic flaw.
Why This Still Matters (Even with Reduced CVSS)
The program ultimately reduced the severity score due to:
- Attack complexity
- Need for scripting and inference
- Limited retention window
That decision is understandable - but it doesn’t negate the lesson.
In real-world environments:
- Attackers automate
- Time windows don’t matter
- Small leaks aggregate into large breaches
Security design must assume capable adversaries, not lazy ones.
Root Cause Analysis
1. Predictable Object Identifiers
Sequential IDs and timestamps are not secrets. They should never be used as sole access controls.
2. Missing Authorization Check
The server never verified:
- Who requested the file
- Whether they owned it
- Whether access was permitted
3. False Sense of Obscurity
The design relied on:
“Nobody will guess the filename.”
History has shown - repeatedly - that this assumption fails.
How This Should Have Been Designed
Strong Object Binding
Every file request should enforce:
- User ownership
- Session association
- Access policy evaluation
Non-Predictable Identifiers
Use:
- Random UUIDs
- Secure object tokens
- One-time, expiring download links
Defense-in-Depth
Even if a filename leaks:
- Authorization checks must still fail
- Access logs should flag anomalies
- Rate limits should slow enumeration
Detection Tips for Security Teams
When reviewing applications, flag endpoints that:
- Accept filenames or IDs directly from the client
- Serve files without permission checks
- Use sequential or timestamp-based naming
- Assume obscurity equals protection
Lessons for Bug Hunters
- “Boring” features hide valuable bugs
- Predictability is often exploitable
- Scripts turn theory into proof
- Clear impact narratives matter as much as PoCs
This vulnerability wasn’t flashy - but it was real.
Lessons for Developers
- Identifiers are not authorization
- Predictable ≠ safe
- Client-controlled references must always be validated
- Storage decisions affect security outcomes
Conclusion
This case study demonstrates how small, reasonable design choices can combine into meaningful security failures.
Sequential IDs.
Readable filenames.
Convenient downloads.
Individually harmless. Together exploitable.
Security isn’t broken by one bad decision - it’s broken by assumptions left unchallenged.

References
- OWASP Top 10: Broken Access Control
- OWASP IDOR Cheat Sheet
- Real-world bug bounty disclosure (anonymized)










